One tree
One tree One life

The data is increasing at an enormous exponential rate. The world produced 181 zettabytes of data in 2025, which is expected to grow massively. Companies produce large amounts of data every second, including customer purchases, application usage, social media activity, and IoT sensor readings.
However, the problem is that most Extract, Transform, Load (ETL) solutions are not up to the job. They slow down, crash when under load, and require continuous patching. 47% of business and IT executives struggle to cope with growing data volumes. To make matters worse, poor data handling can also lead to security risks. In 2023, the average data breach cost was $4.45 million—a severe hit for any business.
If your ETL pipeline is slow, flaky, and expensive, breathe a sigh of relief. Good news: A scalable cloud-based ETL pipeline can fix all that. It does the heavy lifting of automatically handling growing data, optimizing performance, and scaling when needed, without breaking the bank.
Here in this blog, we will walk you through how to build ETL pipeline in the cloud, so that you can manage data efficiently and uncover rich insights.
Let’s get started!
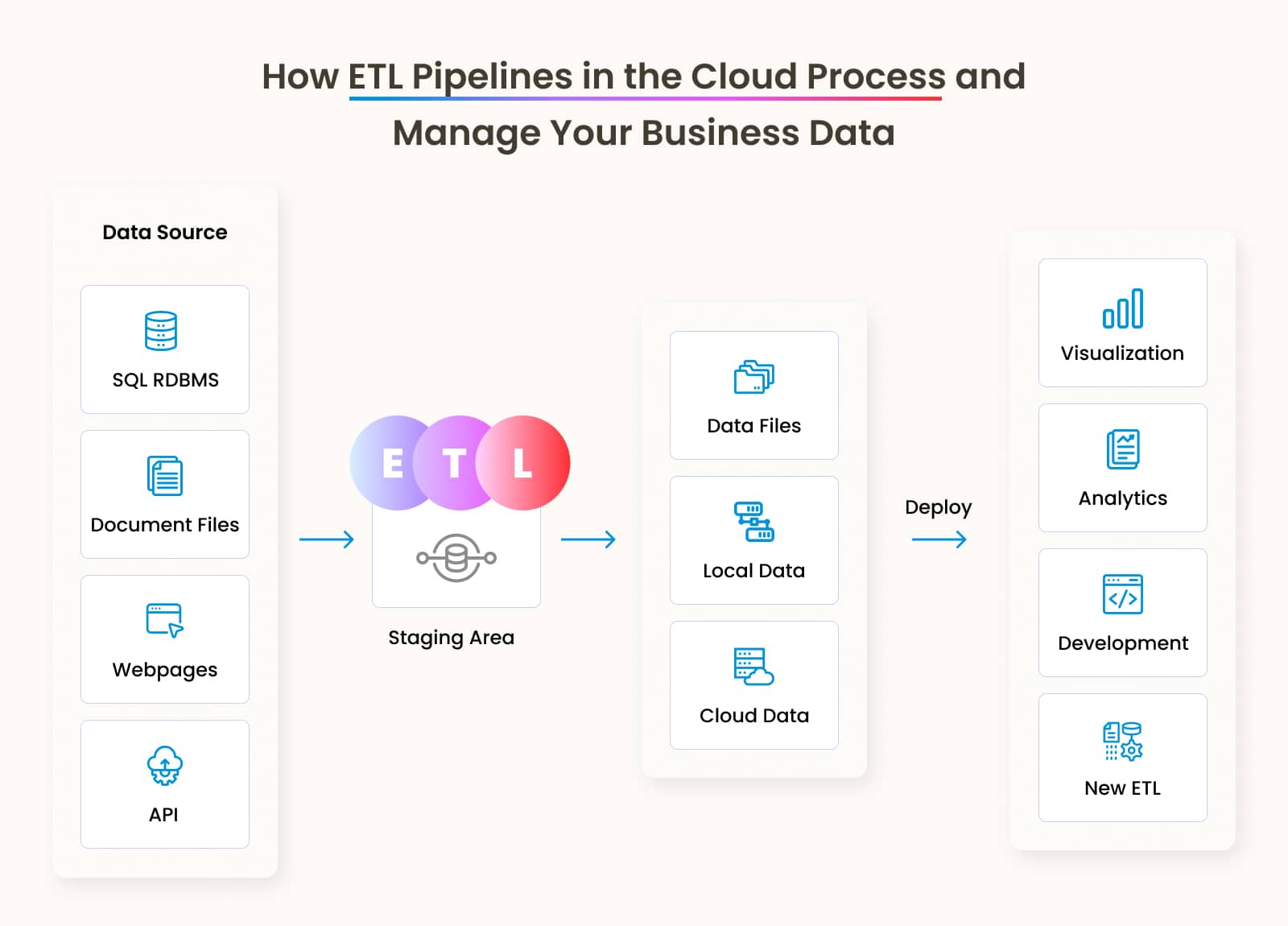
Your business generates ample data, including several sources such as social media, websites, digital customer interactions, etc. This data is not so valuable because of its raw nature, unstructured groups, and formats. Besides, these data are also scattered across multiple platforms. The data collected is undoubtedly a goldmine, but it requires proper analysis. We have bought the Extract, Transform, and Load Pipeline for this. This is how your chunk of data becomes a wealth of information and a roadmap to achieve business growth, expansion, and objectives.
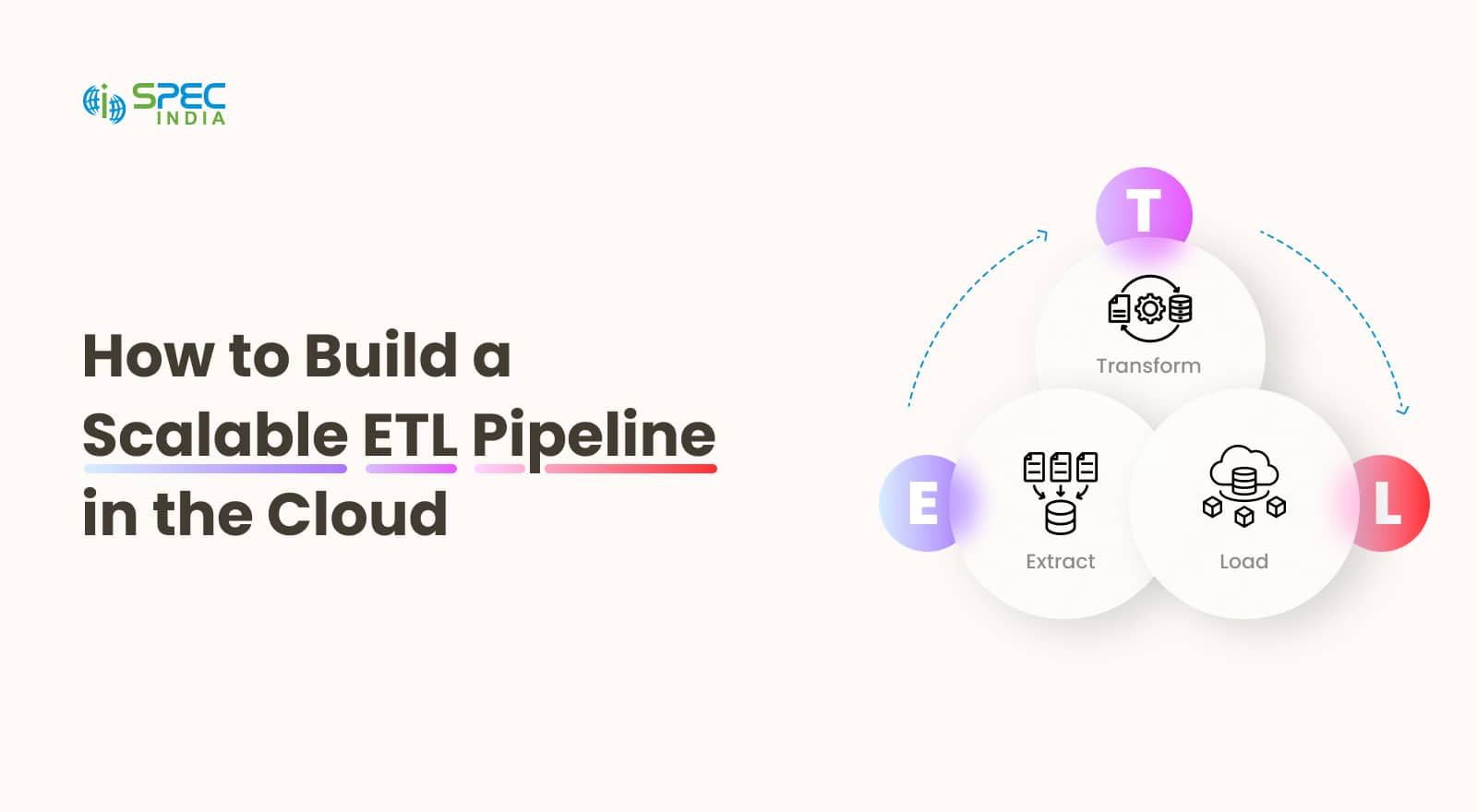
The ETL data pipeline is the process by which raw data moves from one location to another while still maintaining authenticity and accuracy. Three steps are involved in turning raw data into a structured form.
It collects raw data from various sources, such as APIs, files, databases, and cloud storage.
As the name suggests, it cleanses and structures the raw data, making it meaningful and valuable. The process also involves removing duplicates, rectifying errors, and converting data types.
The final step of the ETL pipeline process is to load the final output (structured data) into the data warehouse. Post loading, the data is ready for deep analysis, report generation, and training AI models to determine customer behavioral analysis.
There are two ways to run ELT pipelines: on-premises servers and the cloud. The traditional concept (on-premises servers) has challenges, but the cloud emerges as the solution.
On-premises servers worked well for data integration when businesses generated limited data. However, as data grew rapidly, these servers started causing problems like slow performance, scalability issues, and inefficiencies. That’s where Cloud-backed ETL data pipelines come to light to overcome the challenges. If you seek expert guidance on ETL development services, let’s connect and build a scalable data pipeline architecture.
You don’t need to worry about quantitative data processing with cloud-based servers.
Zero wait time with parallel data processing features in Cloud computing leads to quicker outcomes.
No infrastructure and hardware cost for handling tangible servers; just pay for what you use.
Easily integrates with cloud-based data warehouses like Amazon RedShift, Google BigQuery, and Snowflake.
Cloud has in-built security controls (encryption, two-factor authentication) and compliance with industry standards.
All of the above cloud-based ETL pipeline benefits make the approach worth considering. However, crucial factors must first be considered to verify that the data pipeline is secure, scalable, and effective.
ETL pipeline development consists of several factors, of which data will always be the base. As it grows massively daily, the ETL pipeline architecture requires it to be flexible, scalable, and adaptable to new innovations. Considering that and several others, here is the list of factors for ETL pipeline development.
This is one of the crucial factors to consider in the digital world. Cloud-based warehouses like Amazon RedShift, Google BigQuery, or Azure should be regarded as part of the data-bound era. These tools handle scalability and ensure intact performance while maintaining a heavy workload.
A real-time approach is helpful if you want to detect and prevent fraud, provide customer recommendations based on their preferences, analyze financial charts, or monitor patient vitals. On the other hand, if you have data that doesn’t require immediate attention but are worthy of processing, you can use a batch processing approach.
The ELT pipeline enables strategic business decisions based on data processing. Any glitch in the ETL pipeline performance could delay them, resulting in missed opportunities. Techniques like parallel processing and distributed computing optimize them. With the right cloud services, you can allocate optimal compute resources to receive real-time insights and on-time reporting.
When you are planning to consider an ETL pipeline, one of the core considerations should be a fault-tolerant pipeline. Such pipelines deliver uninterrupted operations despite system failures. Besides, you must also implement checkpoints, automatic retries, and backup systems so that no data is lost and can be recovered in no time.
Quality data is one of the pillars of decision-making. When considering a data pipeline, you must implement data validation, deduplication, and error handling methods to process and filter out only clean, high-quality data. You must also implement data governance policies to monitor the data flow and usage and ensure industry and legal compliance regulations.
When building a data pipeline, ensure it easily integrates with business intelligence tools or cloud data warehouses (Snowflake, Azure Synapse Analytics, Oracle Autonomous Data Warehouse, or IBM Db2 Warehouse). This results in a swift flow of data across varied platforms, making it easier for teams from different departments of your business to access, evaluate, and visualize data without hassle.
Securing confidential data is a top priority, so implement data encryption, masking, and anonymization, OAuth 2.0, firewalls, and secure access control in your data pipeline development. Moreover, you must also consider using the cloud’s advanced security features, which provide security against data theft, leaks, and cyber vulnerabilities.
No matter how much your business expands, only a well-built and scalable ETL data pipeline ensures efficient functioning. Without modern data engineering, handling enormous data becomes challenging, performance delivery is sluggish, and automation fails. Having said that, a prominent and experienced business intelligence services provider is all you need to fix all the bottlenecks and inefficiencies.
Here is a step-by-step breakdown of how the process works for ETL pipeline development:
The first step involves gathering all the sources through which your business generates data, evaluating complexities, and preparing data extraction methods. The sources include databases, CRM systems, cloud apps, APIs, IoT, sensors, and logs with varied formats, structures, and frequencies, which may vary from industry to industry.
Once data sources are determined, the next step is to select the right ETL tools for seamless data extraction, transformation, and loading. Several cloud-based and open-source ETL tools are available. Selecting one depends on factors like data volume, business objectives, processing speed, and overall budget.
To give you a glimpse,
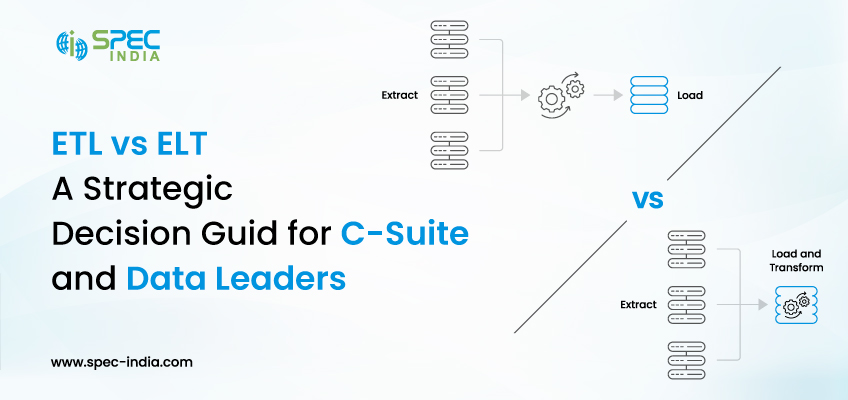
These are just a few ETL tools you can select based on how you want to deal with the available business data. Some businesses benefit from ELT (Extract, Load, Transform) instead of ETL. The approach is advanced and handles enterprise-grade data transformation within cloud data warehouses. If you are unsure which data integration method is appropriate, don’t worry—we have an entire blog on ETL vs. ELT.
The real game begins when data extraction actually happens. Data extraction from various sources is executed in this step, considering efficiency and speed. It happens with:
The transformation part begins once data is extracted and collected from various sources. Here, duplicate entries, errors, and inconsistencies are removed. What is left is accurate, clean, and structured data that offers meaningful information after the loading phase.
The transformation includes:
All the transformed data from the previous step is now set to be loaded into the cloud-backed data lakes. You are all set with your final data, which helps you make strategic business decisions. Use the analysis method wisely and derive a wealth of information to build strategies for your business.
Now comes the step where any business would invest more than required: hiring a workforce for minimal tasks. If you connect with the leading and evolving custom software development company, you can reap the perks of emerging technologies that enable:
Since business growth and success depend on data, its security remains a top priority. You must implement proper security measures, such as data encryption, data masking, access control, authentication, and regulatory compliance.
To efficiently process large volumes of data, building a scalable ETL pipeline is essential while maintaining speed and performance. To achieve this, following a set of best practices is crucial. Below are some key strategies to ensure an optimized and scalable ETL pipeline.
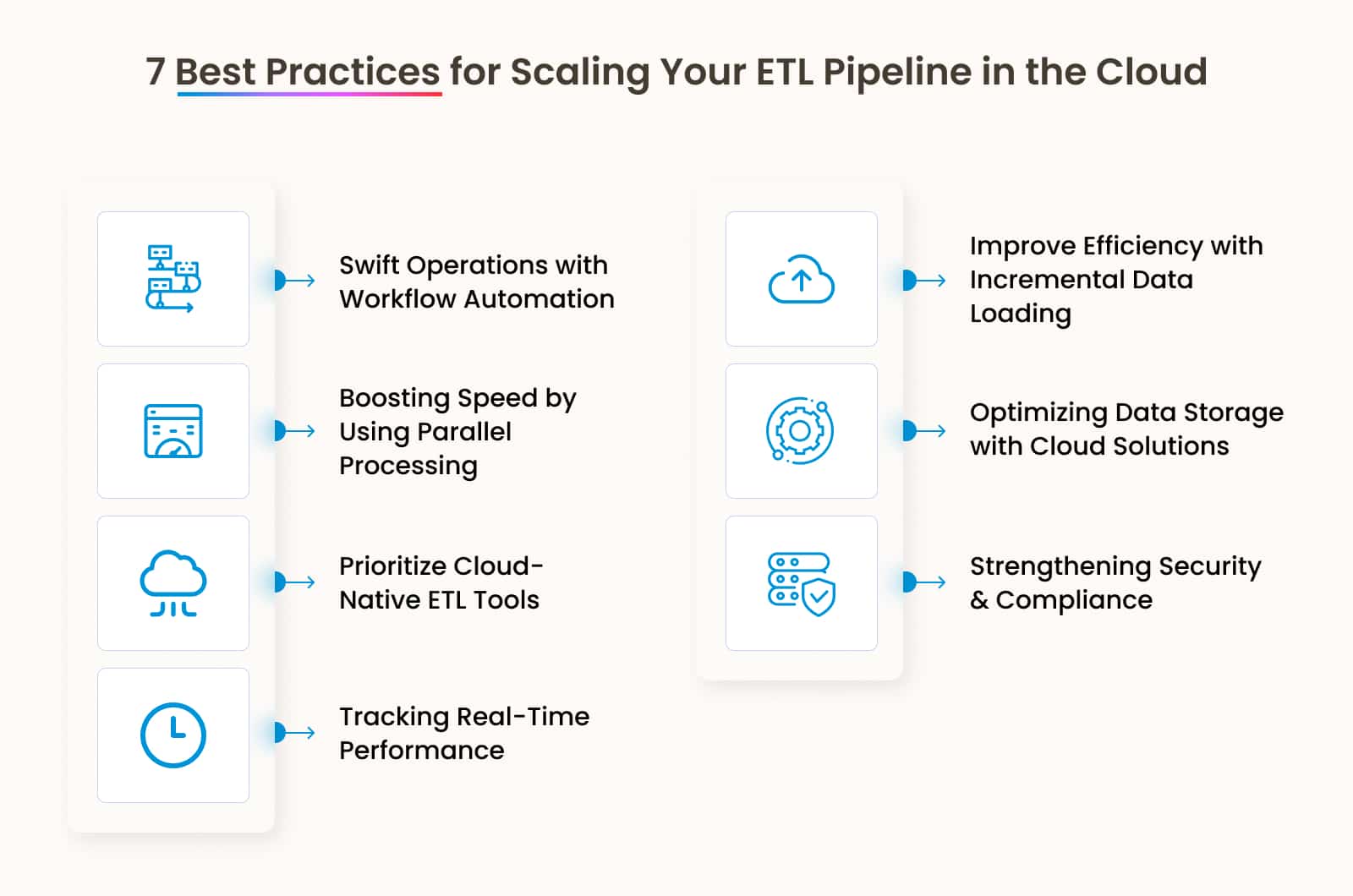
It is advisable to only use cloud-based ETL tools (Snowflake, AWS Glue, Google Dataflow) for scalability, as the business requires and adjusts accordingly to save time and cost.
Parallel processing should be used to handle multiple pieces at once. It results in faster data extraction, transformation, and loading without consuming much time.
Always depend on reliable and prompt cloud data storage like Amazon S3, Azure Blob Storage, and Google Cloud Storage. Besides, make sure to partition and index the data to access what is needed, resulting in faster data processing.
Leverage automation tools for scheduling ETL tasks, regain command over failed jobs, and monitor performance, ensuring continuous data flow.
Load only updated or new data using change data capture (CDC) and reduce cost.
Keep track of errors and system delays and ensure receiving notifications/logs to detect and prevent bottlenecks before the data integration pipeline runs out.
Ensuring data encryption, access control, and authentication are implemented correctly is crucial. Besides, adhering to compliances like HIPAA, GDPR, SOC 2, and CCPA is crucial.
The ETL pipeline development roadmap contains several pitfalls, but you needn’t worry because we have definite solutions. Let’s explore each one in detail.
Slow Data Processing
High Infrastructure Cost
Data Inconsistency
System Downtime & Failure
Security & Compliance Risks
To properly manage increasing data volumes, a scalable ETL pipeline is crucial. Businesses can facilitate smooth data transfer, real-time analytics, and cost efficiency through cloud-based systems, automation, and best practices.
We at SPEC INDIA offer customized ETL solutions to suit your business’s needs. Our data engineering team crafts, develops, and elevates high-performance, scalable, and secure cloud-based ETL pipelines. Whether automation, real-time processing, or transfer, we guarantee your data flows effortlessly and provide rich insights.
Want to refresh your data infrastructure? Contact our software engineers today and let us help you create an ETL pipeline that scales with your business!
SPEC INDIA, as your single stop IT partner has been successfully implementing a bouquet of diverse solutions and services all over the globe, proving its mettle as an ISO 9001:2015 certified IT solutions organization. With efficient project management practices, international standards to comply, flexible engagement models and superior infrastructure, SPEC INDIA is a customer’s delight. Our skilled technical resources are apt at putting thoughts in a perspective by offering value-added reads for all.
“SPEC House”, Parth Complex, Near Swastik Cross Roads, Navarangpura, Ahmedabad 380009, INDIA.
“SPEC Partner”, 350 Grove Street, Bridgewater, NJ 08807, United States.
This website uses cookies to ensure you get the best experience on our website. Learn more